これは Xpress AI と Agents の Advent Calendar 2024 の 20 日目です。
大規模言語モデル(LLM)は人工知能に革命をもたらしましたが、高性能かつ開発の拡張性を維持しながら実装することは、依然として困難なエンジニアリング課題として残っています。 XpressAIでは、この課題に挑戦する最新プロジェクト、Llama4Sをご紹介できることを嬉しく思います。
Llama4SはScala 3で書かれた、シンプルでありながら非常に実用的なLlama 3.x推論エンジンで、軽量、高性能、そして柔軟な設計となっています。 llama3.javaプロジェクト、そしてそのプロジェクト自体がAndrew Karpathyのllama2.cと、LLMの実装に関する彼の講義に触発され、 私たちのアプローチは、計算効率とコードの明確さのバランスを取った簡潔な実装を優先し、AIモデル推論において現在可能な境界線を押し広げることを目指しています。
以下は、Llama4Sの動作のスクリーンショットです:

Scala 3 採用の論理的根拠
Scala 3は、Llama4Sに強力な基盤を提供し、開発者にLLMアルゴリズムを実装するための優雅で表現力豊かな、そしてスケーラブルな言語を提供します。 この言語の高度な型システムと関数型プログラミング機能により、より一般的なプログラミング言語で提供される機能と比較して、より堅牢で簡潔なコードが可能になります。 ユニオン型、不透明型、改良されたパターンマッチングなどの機能により、複雑な機械学習の抽象化をより正確に型レベルでモデル化することが可能となり、実行時エラーを減少させ、コードの保守性を向上させます。
同時に、JVMエコシステムは、成熟したプロファイリングツール、堅牢なガベージコレクション、そしてパフォーマンスクリティカルなコードパスを動的に最適化できるジャストインタイム(JIT)コンパイルを含む、 機械学習インフラストラクチャに重要な利点をもたらします。ScalaのJavaとのシームレスな相互運用性により、開発者は既存のJavaとScalaのライブラリとツールの両方を活用でき、機械学習開発のための豊かなエコシステムを生み出すことができます。
さらに、Scala 3は高度なメタプログラミングとコンパイル時のコード生成機能を備えており、これらはJVM上の大規模な分散LLMアプリケーションを可能にする潜在力があると私たちは考えています。 マクロとインライン機能により、洗練されたコード変換と最適化がコンパイル時に解決可能となり、実行時のオーバーヘッドを削減し、開発者に負担をかけることなく、より複雑なモデルアーキテクチャを実現する可能性があります。
このように、Llama4SはJVM上の機械学習における最先端の可能性を探求するための実験の場として機能し、現代のプログラミング言語がAI/MLフレームワークの設計の境界をどのように押し広げることができるかを実証しています。
性能と実装の課題
このように、Llama4SはJVM上の機械学習における最先端の可能性を探求するための実験の場として機能し、現代のプログラミング言語がAI/MLフレームワークの設計の境界をどのように押し広げることができるかを実証しています。 Llama4Sは、JVMにSIMDレベルのプログラミング機能を導入するJava Vector API(JEP 469)を通じて、量子化テンソルの高速な一般行列-ベクトル乗算をサポートしています。 また、GraalVMコンパイラ下でコンパイルされた際に、同コンパイラが提供する追加の高度な最適化を活用してより最適なパフォーマンスを実現します。
Llama4Sとllama3.javaはどちらもJVMにコンパイルされるため、そのパフォーマンス特性は比較可能です。 参考として、現在最も広く使用されているC++ベースのLLM推論エンジンであるllama.cppとの比較のために、llama3.javaのパフォーマンスチャートをここに含めています:

しかしながら、JEP 469が利用可能であるにもかかわらず、現在のJVMの実装では、Scalaコンパイラが出力するベクトル化関連のバイトコードを最適化することに苦心していることが観察されました。 私たちの調査により、メソッドの配置や言語固有の実装の詳細が実行時のパフォーマンスに劇的な影響を与え得ることについて、驚くべき知見が明らかになりました。
以下は3つのパフォーマンストレースで、それぞれがQ4_0テンソルに対する同じベクトル内積演算の微妙に異なるバリアントをプロファイリングしたものです。
すべてのコードは、2.3 GHz 8コアIntel Core i9プロセッサと16GBのRAMを搭載した2019年のMacBook Pro上で、Llama-3.2-1B-Instruct-Q4_0モデルを使用して実行されました。
最初のトレースに対応するコードでは、ベクトル内積の実装はQ4_0Tensorクラス内にインスタンスメソッドとして定義されていました:
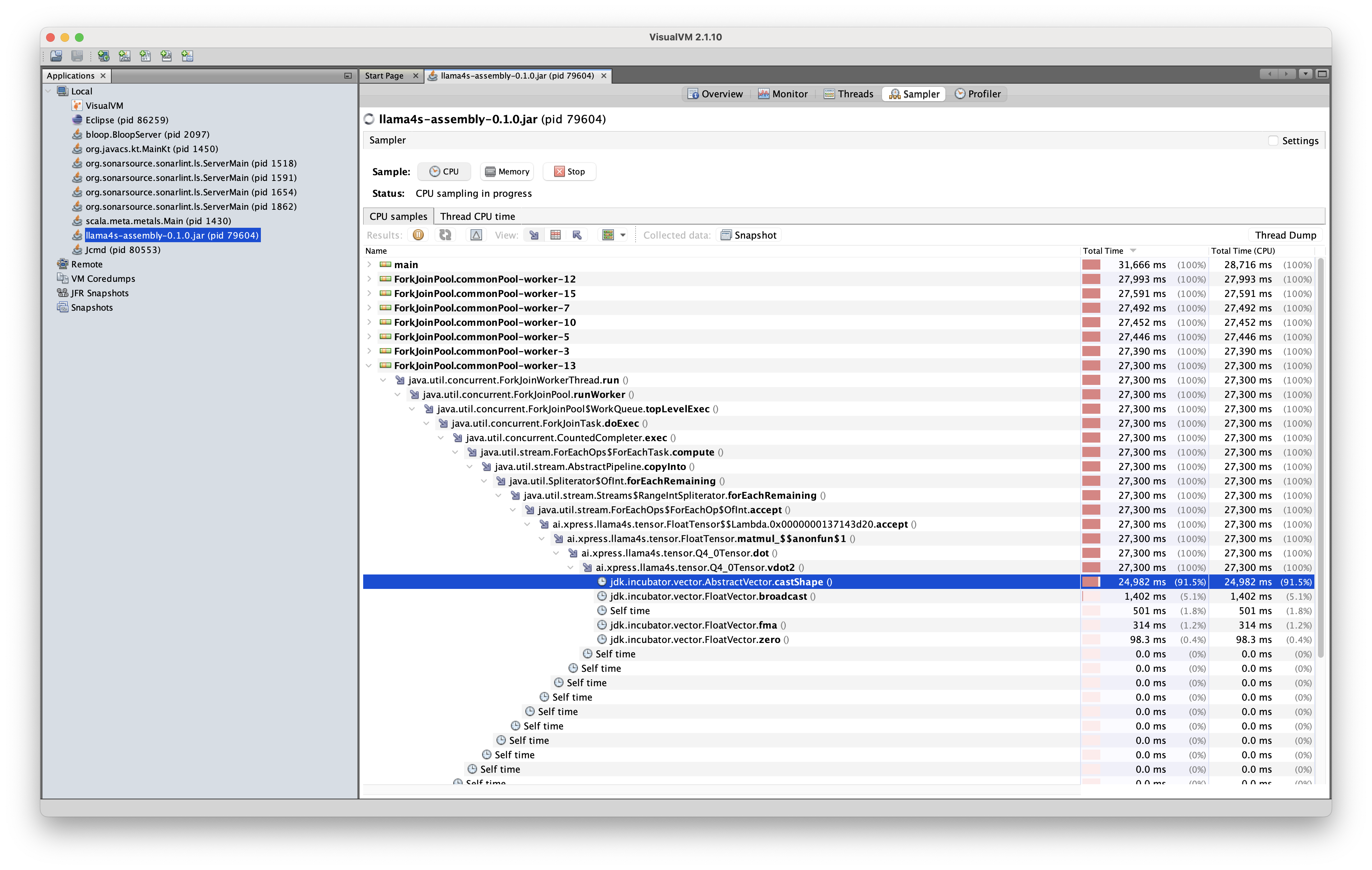
この場合、JVMはSIMDレーンのシェイプキャスト操作を最適化することができず、このボトルネックが計算時間の約90%を消費しました。 その結果、推論エンジンは約5秒に1トークンの速度でしか出力することができず、実用的な使用には適さない実装となりました。
2番目のトレースに対応するコードでは、実装は同じでしたが、Q4_0Tensorクラスの外部に静的メソッドとして定義されていた点が異なっていました:
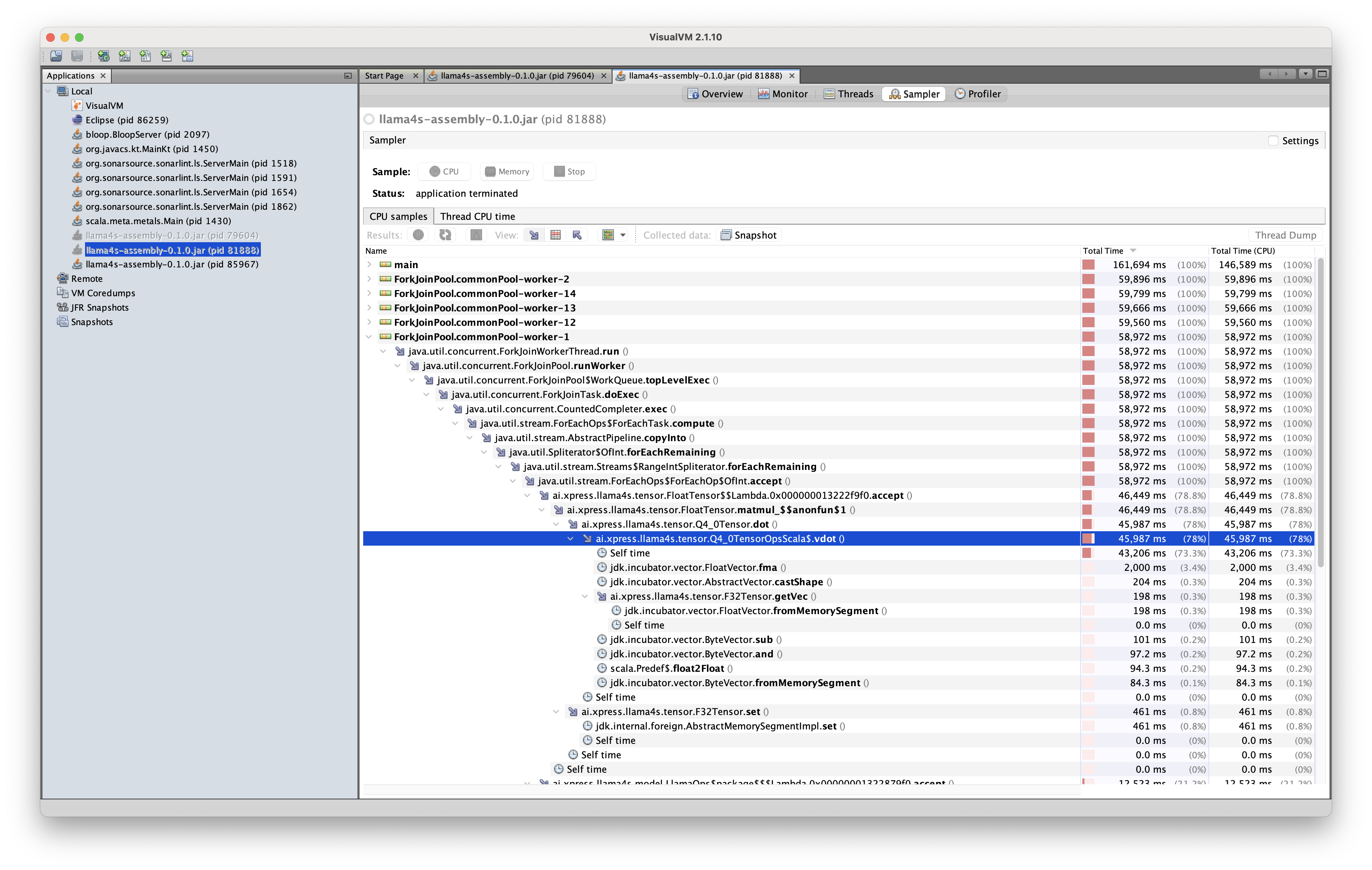
注目すべきことに、この実装ではシェイプキャスト操作が最適化により除去され、推論エンジンは1秒あたり約3トークンの速度で出力することができました。 パフォーマンスは、実装をJavaで静的メソッドとして定義した場合にさらに改善されました:
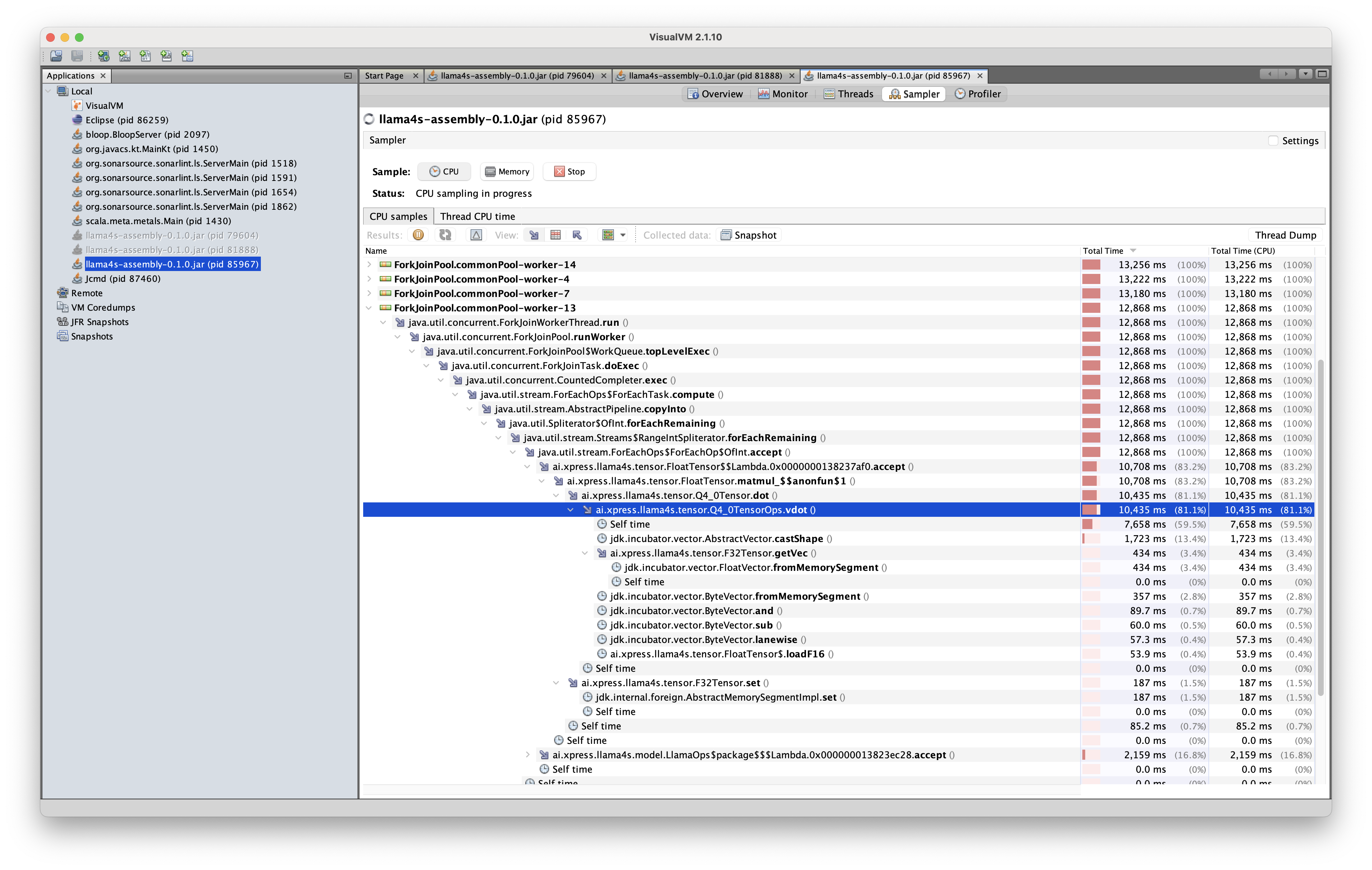
このコード変更により、トークン出力速度は1秒あたり5トークンに改善されました。
これらの実験は、現代のプログラミング言語とAPIがパフォーマンス向上のための強力なツールを提供している一方で、 最適なパフォーマンスを達成するには、コンパイラの動作とランタイムの特性についてより深い理解が必要であることを示しています。 私たちはJava Vector APIを意図された通りに使用していますが、JVMはまだその使用に関連するコードパターンを完全に識別し最適化することができていません。
今後の取り組み
Llama4Sは、単なるもう一つのLLM推論エンジンではなくて、現代のプログラミング言語とランタイム環境をどのように活用して機械学習インフラストラクチャの境界を押し広げることができるかという戦略的な探求を体現しています。 Scala 3を選択しJVMエコシステムを採用することで、私たちは十分な性能を持つ推論エンジンを作成しただけでなく、分散機械学習システム開発の新しい可能性を切り開きました。
今後、Llama4Sには以下のような発展の道筋を検討しています:
- ベクトル化の改善: 私たちのパフォーマンストレースは、JVMのベクトル化戦略を改善する機会を浮き彫りにしています。これらの知見を広くOpenJDKコミュニティと共有し、Java Vector APIの実装改善に貢献することを目指しています。
- JavaCPP統合: 機械学習分野の既存のネイティブライブラリと高性能なバインディングを作成するためのJavaCPPの使用を検討しています。これにより、Java Vector APIが不十分な場合でも、Llama4Sはハードウェアを最大限に活用することができます。
- 分散LLM機能: Scala 3のメタプログラミング機能は、スケーラブルな分散機械学習フレームワークを開発するための有望な基盤を提供します。Llama4Sはこれらの機能を探求するためのテストベッドとして機能します。
- より広範なモデルサポート: 現在Llama4SはLlama 3.xモデルに焦点を当てていますが、より幅広いLLMモデルのサポートを拡大する計画です。
- コミュニティ参加: Llama4Sをオープンソース化することで、開発者や研究者が私たちの実装に貢献し、学ぶことができる協力的な環境を育成することを望んでいます。
開発者、研究者、AIエンサジアストの皆様をLlama4Sリポジトリの探索に招待し、皆様の知見を共有し、機械学習インフラストラクチャの未来を共に再構築することを期待しています。 まだ初期段階にもかかわらず、Llama4SはすでにXpressAIの複数のプロジェクトで活用されており、実世界のアプリケーションでその価値を証明しています。Xpress AIとAgents Adventシリーズを通じて公開予定の、実際に動作するLlama4Sのデモンストレーションにご期待ください!